Analyse de certains arguments avançant qu'il ne faut pas prendre la sécurité de l'IA au sérieux
Il y a environ un an, quelques mois après avoir pris publiquement position aux côtés de plusieurs pairs pour mettre en garde le public contre les dangers liés aux capacités sans précédent des systèmes d'IA très puissants, j'ai publié un billet de blog intitulé Questions fréquentes sur les risques catastrophiques liés à l’IA, qui constituait une suite à mon billet précédent sur les IA nocives, dans lequel je commençais à expliquer pourquoi la sécurité de l'IA devait être prise au sérieux. Entre-temps, j'ai participé à de nombreux débats, notamment avec mon ami Yann LeCun, dont les points de vue sur certaines de ces questions sont très différents des miens. J'ai également beaucoup appris sur la sécurité de l'IA, sur les manières dont différents groupes de personnes réfléchissent à cette question, ainsi que sur les nombreux points de vue concernant la réglementation et sur les efforts déployés par de puissants lobbies pour s'y opposer. Si la question est si vivement débattue, c'est parce que les enjeux sont majeurs : selon certaines estimations, on parlerait de quadrillions de dollars de valeur actuelle nette, sans compter la possibilité d’un pouvoir politique suffisamment important pour perturber de manière significative l'ordre mondial actuel. J'ai publié un article sur la gouvernance multilatérale des laboratoires d'intelligence artificielle générale et j'ai passé beaucoup de temps à réfléchir aux risques catastrophiques de l'IA et à leur atténuation, tant du point de vue technique que du point de vue de la gouvernance et de la politique. Au cours des sept derniers mois, j'ai présidé (et je continue de présider) le Rapport scientifique international sur la sécurité de l'IA avancée (ci-après « le rapport »), auquel ont participé un groupe de 30 pays, l'UE et les Nations unies, ainsi que plus de 70 experts internationaux, afin de synthétiser l'état de la science en matière de sécurité de l'IA et d'illustrer la grande diversité des points de vue sur les risques et les tendances en matière d'IA. Aujourd'hui, après une année intense consacrée à ces questions cruciales, je souhaite revenir sur certains arguments avancés concernant les risques catastrophiques potentiels associés aux systèmes d'IA que l'on anticipe pour l'avenir, et faire part de mes dernières réflexions.
Il y a de nombreux risques associés à la course menée par plusieurs entreprises privées et d’autres entités vers l'IA aux capacités similaires à celles des humains (intelligence artificielle générale ou AGI en anglais) et au-delà (la super-intelligence artificielle ou ASI pour Artificial Super-Intelligence en anglais). Veuillez consulter « le rapport » pour une large couverture des risques qui comprend les questions actuelles des droits humains et les menaces à la vie privée, la démocratie, les droits d'auteur, les préoccupations concernant la concentration du pouvoir économique et politique, et, bien sûr, les utilisations malveillantes et dangereuses. Bien que les experts ne soient pas tous d'accord sur la probabilité des différents scénarios, nous pouvons généralement convenir que certains risques majeurs, comme l'extinction de l'humanité par exemple, seraient tellement catastrophiques s'ils se produisaient qu'ils nécessitent une attention particulière, ne serait-ce que pour s'assurer que leur probabilité est infinitésimale. D'autres risques, comme les menaces graves qui pèsent sur les démocraties et les droits humains, méritent également beaucoup plus d'attention qu'ils n'en reçoivent actuellement.
La chose la plus importante à constater, à travers tout le vacarme des discussions et des débats, est un fait très simple et indiscutable : alors que nous coursons vers l'AGI, ou même l'ASI, personne ne sait actuellement comment s'assurer qu'une telle AGI ou ASI se comporterait moralement, ou du moins qu'elle se comporterait comme prévu par ses développeurs et ne se retournerait pas contre les humains. C'est peut-être difficile à imaginer, mais visualisez un instant ce scénario :
Advenant la présence d'entités plus intelligentes que les humains ayant leurs propres objectifs : sommes-nous sûrs qu'elles agiront pour notre bien-être?
Pouvons-nous collectivement courir ce risque sans en être sûrs? Certains avancent toutes sortes d'arguments pour expliquer pourquoi nous ne devrions pas nous inquiéter (je les développerai plus loin), mais ils ne sont pas en mesure de fournir une méthodologie technique permettant de contrôler, de manière démontrable et satisfaisante, les systèmes d'IA généralistes avancés, mêmes ceux qui existent actuellement, et encore moins des garanties ou des assurances scientifiques fortes et claires qu'avec une telle méthodologie, une ASI ne se retournerait pas contre l'humanité. Cela ne signifie pas qu'il est impossible de découvrir un moyen d'aligner et de contrôler l'IA à l'échelle de l'ASI, et je soutiens en fait ci-dessous que la communauté scientifique et la société dans son ensemble devraient déployer un effort collectif massif pour le découvrir.
De plus, même si l'on connaissait le moyen de contrôler une ASI, il manquerait toujours des institutions politiques pour s'assurer que le pouvoir de l'AGI ou de l'ASI ne soit pas utilisé de manière abusive par des humains contre d'autres humains à une échelle catastrophique, pour détruire la démocratie ou provoquer un chaos géopolitique et économique ou une dystopie. Nous devons faire en sorte qu'aucun être humain, aucune entreprise ni aucun gouvernement ne puisse abuser du pouvoir de l'AGI au détriment du bien commun. Nous devons nous assurer que les entreprises n'utilisent pas l'AGI pour manipuler leurs gouvernements, que les gouvernements ne l'utilisent pas pour opprimer leurs peuples et que les nations ne l'utilisent pas pour dominer au niveau international. Parallèlement, nous devons veiller à éviter les accidents catastrophiques dus à la perte de contrôle des systèmes de niveau AGI, où que ce soit sur la planète. Tout ceci peut être appelé le problème de coordination, c'est-à-dire la politique de l'IA. Si le problème de coordination était parfaitement résolu, la résolution du problème d'alignement et de contrôle de l'IA ne serait pas une nécessité absolue : nous pourrions « simplement » appliquer collectivement le principe de précaution et éviter de faire des expériences partout où il existe un risque non négligeable de construire des AGI incontrôlées. Mais bien sûr, l'humanité n'a pas une pensée unique, mais se compose plutôt de milliards d’esprits, de volontés, de pays et d'entreprises ayant chacun leurs objectifs : la dynamique de tous ces intérêts personnels et de ces facteurs psychologiques ou culturels nous entraîne actuellement dans une course dangereuse vers de plus grandes capacités d'IA, sans la méthodologie et les institutions nécessaires pour atténuer suffisamment les risques les plus importants, tels qu'une utilisation malveillante catastrophique ou une perte de contrôle. Sur une note plus positive, si les problèmes du contrôle et de la coordination de l'IA sont tous deux résolus, je crois qu'il y a de fortes chances que l'humanité bénéficie énormément des avancées scientifiques et technologiques qui pourraient en découler, notamment dans les domaines de la santé, de l'environnement et de l'amélioration des perspectives économiques pour la majorité des humains (en commençant idéalement par ceux qui en ont le plus besoin).
Toutefois, à l'heure actuelle, nous nous dirigeons à toute allure vers un monde composé d'entités plus intelligentes que les humains et qui poursuivent leurs propres objectifs, sans que les humains disposent d'une méthode fiable pour s'assurer que ces objectifs sont compatibles avec les objectifs collectifs humains. Néanmoins, au cours de mes conversations sur la sécurité de l'IA, j'ai entendu divers arguments visant à soutenir une conclusion « dépourvue d'inquiétude ». Ma réponse générale à la plupart de ces arguments est, qu'étant donné les arguments de base convaincants qui permettent d'expliquer pourquoi la course vers l'AGI pourrait conduire à des dangers - même sans certitude, et étant donné les enjeux élevés, nous devrions chercher à obtenir des preuves très solides avant de conclure qu'il n'y a pas lieu de s'inquiéter. Souvent, je trouve que ces arguments ne répondent absolument pas à cette exigence. Je présente ci-dessous certains de ces arguments et explique pourquoi ils ne m'ont pas convaincu que nous pouvons ignorer les risques catastrophiques potentiels de l'IA. Bon nombre des arguments «dépourvus d'inquiétude » que j'ai entendus ou lus ne sont pas des arguments solides, mais relèvent plutôt de l'intuition d'individus qui sont convaincus qu'il n'y a pas de danger, mais qui n'offrent pas d'explications logiques convaincantes. Sans disposer de tels arguments pour nier l'importance de la sécurité de l'IA, et compte tenu de l'importance capitale de notre bien-être global et de l'incertitude quant à l'avenir, la prise de décision rationnelle requiert de l'humilité, la reconnaissance de notre incertitude épistémique et le respect de la théorie de la décision scientifique, qui conduit au principe de précaution. Mais j'ai l'impression que nous n'agissons pas ainsi : certes, les risques extrêmes liés à l'IA sont davantage discutés aujourd'hui et ne sont plus automatiquement ridiculisés dans le discours public. Mais nous ne les prenons pas encore assez au sérieux. De nombreuses personnes, y compris des décideurs, sont désormais conscientes que l'IA peut présenter des risques catastrophiques, voire existentiels. Mais dans quelle mesure arrivent-elles à imaginer ce que cela pourrait signifier? Dans quelle mesure sont-elles prêtes à prendre des mesures non conventionnelles pour atténuer ces risques? Je crains que, si l'engagement public et politique à l'égard des risques liés à l'IA demeure au même niveau, nous risquons collectivement de nous diriger - possiblement en courant - à l'aveugle au sein d'un brouillard derrière lequel pourrait se cacher une catastrophe qui était envisagée par plusieurs, mais qui n'aura pas été suffisamment priorisée en termes de prévention.
Pour les personnes qui pensent que l'AGI et l'ASI sont impossibles ou ne seront pas atteints avant des siècles
L'une des objections soulevées pour ne pas prendre au sérieux les risques liés à l'AGI et l’ASI est que nous n’y parviendrons jamais (ou seulement dans un avenir lointain). Cela prend souvent la forme d'affirmations telles que « les IA ne font que prédire le mot suivant », « les IA ne seront jamais conscientes » ou « les IA ne peuvent pas avoir une véritable intelligence ». Je trouve la plupart de ces affirmations peu convaincantes, car elles confondent souvent deux ou plusieurs concepts et passent donc à côté de l'essentiel. Par exemple, la conscience n’est pas bien comprise et il n'est pas clair qu’elle soit nécessaire pour atteindre l'AGI ou l'ASI. Sa présence n'est donc pas nécessairement essentielle pour que des risques existentiels de l’AGI se matérialisent. Ce qui comptera le plus et reste sur le plancher des vaches, ce sont les capacités et les intentions des systèmes ASI. S'ils peuvent tuer des humains (c'est une capacité parmi d'autres qui peut être apprise ou déduite d'autres compétences) et s'ils ont un tel objectif (des systèmes d'IA guidés par des objectifs existent déjà), cela pourrait être très dangereux, à moins qu'un moyen de l'empêcher ou des contre-mesures ne soient trouvés.
Je trouve également peu convaincantes des affirmations telles que « les IA ne peuvent pas avoir une véritable intelligence » ou « les IA se contentent de prédire le mot suivant ». Je reconnais que si l'on définit la « véritable » intelligence comme étant « la façon dont les humains sont intelligents », on peut conclure que les IA n'ont pas de « véritable » intelligence - leur façon de traiter l'information et de raisonner est différente de la nôtre. Mais dans une conversation sur les risques catastrophiques potentiels de l'IA, cette façon d'aborder la question est une distraction. Ce qui importe, c'est de savoir ce que l'IA peut accomplir. Quelle est sa capacité à résoudre les problèmes? C'est ainsi que je conçois l'« AGI » et l'« ASI » - un niveau de capacités auquel une IA est aussi bonne, voire meilleure, qu'un expert humain pour pratiquement n'importe quelle tâche cognitive (à l'exclusion des problèmes qui nécessitent des actions physiques). La manière dont l'IA en est capable ne change rien à l'existence du risque. Si l'on examine les capacités des systèmes d'IA au fil des décennies de recherche, on constate une tendance très nette à l'augmentation des capacités. Il y a aussi le niveau actuel des capacités de l'IA, avec un très haut niveau de maîtrise du langage et du matériel visuel, et de plus en plus de capacités dans une plus grande variété de tâches cognitives. Veuillez également consulter le « rapport » pour de plus amples informations, y compris sur les désaccords concernant les capacités actuelles réelles. Enfin, il n'y a aucune raison scientifique de croire que l'humanité constitue la forme la plus aboutie d'intelligence : en fait, pour de nombreuses tâches cognitives spécialisées, les ordinateurs surpassent déjà les humains. Par conséquent, même le niveau ASI est plausible (bien qu'il soit impossible de savoir dans quelle mesure) et, à moins de s'appuyer sur des arguments fondés sur des croyances personnelles plutôt que sur la science, la possibilité de l'AGI et de l'ASI ne peut être exclue.
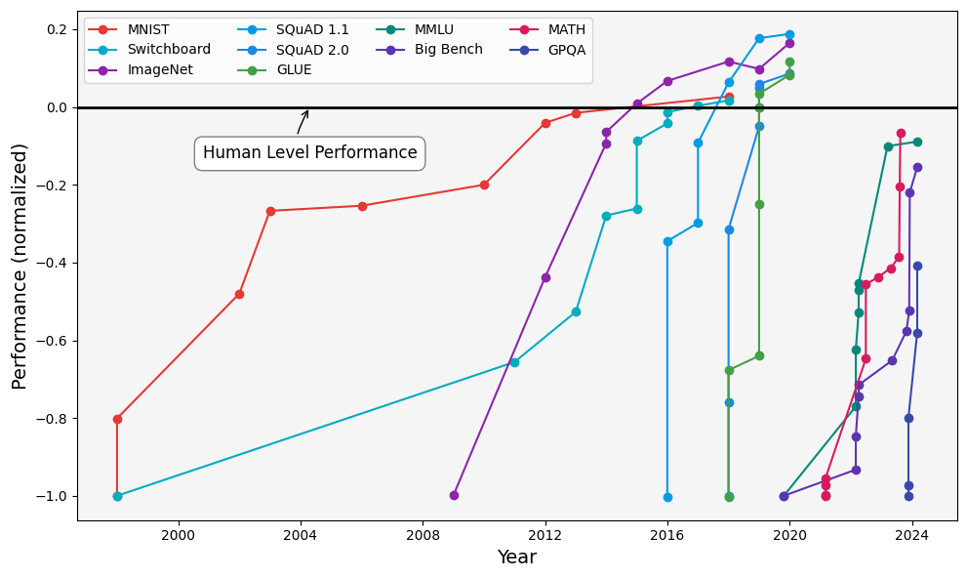
Performances des modèles d'IA selon divers critères de référence entre 2000 et 2024, notamment la vision par ordinateur (MNIST, ImageNet), la reconnaissance vocale (Switchboard), la compréhension du langage naturel (SQuAD 1.1, MNLU, GLUE), l'évaluation de modèles de langage général (MMLU, Big Bench et GPQA), et le raisonnement mathématique (MATH). De nombreux modèles dépassent les performances humaines (ligne noire continue) en 2024. Kiela, D., Thrush, T., Ethayarajh, K., & Singh, A. (2023) « Plotting Progress in AI ».
Pour les personnes qui pensent que l'AGI est possible, mais seulement dans plusieurs décennies
Un autre argument souvent évoqué est qu'il n'est pas nécessaire de réglementer pour protéger le public des risques liés à l'AGI puisque celle-ci n'a pas encore été atteinte et qu'il est impossible de savoir quelle forme elle prendra. Je trouve cet argument peu convaincant pour deux raisons : premièrement, il est impossible d'être certain que l'AGI ne sera pas atteinte en ajoutant une couche d’innovations techniques aux méthodes actuelles, et les tendances en matière de capacités continuent de pointer vers l'AGI. Deuxièmement, et c'est le plus important, le moment où l'AGI sera atteinte est inconnu, alors que la législation, les instances réglementaires et les traités nécessitent de nombreuses années, voire des décennies, pour être mis en place. De plus, qui pourrait affirmer en toute honnêteté et en toute humilité que ces progrès n'arriveront certainement pas à court terme? Je reconnais que lorsque nous comparons les systèmes d'IA à usage général les plus avancés et l'intelligence humaine, nous constatons des écarts qui pourraient nécessiter de nouvelles percées dans la recherche en IA afin d'être comblés. En particulier, je reconnais que les systèmes de dialogue actuels ne raisonnent ni ne planifient aussi bien que les humains et qu'ils présentent des comportements souvent incohérents. Mais nous disposons déjà de systèmes capables de raisonner et de planifier mieux que les humains, comme AlphaGo, même si le domaine de leurs connaissances est limité et que leurs connaissances de base n'ont pas été apprises, mais codées (les règles du jeu de Go, par exemple). L'avancée nécessaire consisterait donc à combiner l'acquisition de connaissances et les compétences linguistiques de GPT-4 avec la capacité de planification d'AlphaGo. Par ailleurs, de nombreux humains ne raisonnent pas très bien et peuvent « halluciner » des réponses qui ne sont pas fondées sur la réalité, ou agir de manière incohérente, deux faiblesses bien étudiées des LLM, de sorte que nous ne sommes peut-être pas aussi éloignés que certains le pensent du spectre des capacités humaines. Un point encore plus important à noter est qu'avant l'arrivée de ChatGPT, la plupart des chercheurs en IA, y compris moi-même, ne s'attendaient pas à ce que ce niveau de capacités apparaisse avant des décennies, et les trois experts les plus cités dans le domaine de l'IA s'inquiètent maintenant de ce que cela pourrait signifier. Compte tenu de cette incertitude, je recommande que nous gardions un esprit ouvert : les progrès pourraient se poursuivre au même rythme, ou ils pourraient s'arrêter et il pourrait falloir des décennies pour atteindre l'AGI. La seule position rationnelle compatible avec toutes ces preuves est l'humilité et la planification en fonction de cette incertitude.
Une tendance que j'ai parfois observée au fil de certaines discussions et que je trouve trompeuse est celle de raisonner comme si les capacités de l'IA allaient toujours demeurer à leur niveau actuel : nous devons envisager des scénarios et des trajectoires plausibles concernant les progrès de l'IA afin de nous préparer aux plus dangereux d'entre eux et prendre la mesure des tendances telles que celles présentées dans le graphique ci-dessus.
Pour les personnes qui pensent que nous pourrions atteindre l'AGI, mais pas l'ASI
Certains pensent que l'intelligence humaine constitue le niveau d'intelligence le plus élevé possible et que les systèmes d'IA ne seront pas en mesure d'égaler toutes nos capacités. Cela ne peut être réfuté, mais semble néanmoins très improbable, comme je l'ai expliqué ci-dessus dans la première section titrée, et comme Geoff Hinton l'a expliqué de manière éloquente en comparant les capacités du calcul analogique (comme dans notre cerveau) à celles du calcul digital (comme dans les ordinateurs). De plus, il n'est pas nécessaire de couvrir toutes les capacités humaines pour en arriver à des scénarios présentant un risque existentiel dangereux : il suffit de concevoir des systèmes d'IA qui correspondent aux capacités humaines les plus élevées en termes de recherche en IA. Une seule IA entraînée dotée de cette capacité pourrait produire des centaines de milliers d'instances capables de travailler sans interruption (tout comme un seul GPT-4 peut servir des millions de personnes en parallèle parce que l'inférence peut être trivialement parallélisée), ce qui multiplierait immédiatement les effectifs de recherche en IA par un grand nombre (éventuellement au sein d'une seule et même entreprise). Cela permettrait d'effectuer de grands bonds dans la recherche en IA, dans une direction qui comporte de nombreuses variables inconnues, alors que nous pourrions passer de l'AGI à l'ASI en l'espace de quelques mois. Cette main-d'œuvre plus nombreuse dans le domaine de la recherche en IA pourrait construire des IA plus performantes et accélérer les progrès davantage, etc. Dans le même ordre d'idées, on peut faire valoir que la robotique accuse actuellement un retard considérable par rapport aux capacités plus cognitives de l'IA. Une fois encore, si l'on examine les tendances et l'état actuel, on constate que les progrès en robotique se poursuivent et qu'ils pourraient être accélérés par l'atteinte de l’AGI et de l'ASI car une AGI compétente en recherche en robotique accélèrerait ces avancées. Ces progrès doivent absolument être surveillés attentivement, car nous pouvons imaginer que les systèmes d'IA avec des objectifs d'auto-préservation qui n'auraient plus besoin des humains parce qu'ils pourraient contrôler des robots pour accomplir le travail physique auraient théoriquement une motivation claire pour se débarrasser complètement de l'humanité afin d'exclure la possibilité que des humains les désactivent.
Pour les personnes qui pensent que les AGI et l'ASI seront bienveillantes à notre égard
J'espère vraiment que ces attentes se matérialiseront, mais la recherche en informatique sur la sécurité de l'IA pointe dans la direction opposée et, en l'absence d'une démonstration claire, la gestion de risque exige que l'on prenne des précautions contre les mauvais scénarios plausibles. Une IA ayant un objectif d'auto-préservation résisterait à sa mise hors service et, afin de minimiser la probabilité d'être mise hors service, une stratégie plausible consisterait pour elle à nous contrôler ou à se débarrasser de nous pour s'assurer que nous ne mettions pas son avenir en péril. Les accords entre entités qui doivent négocier une ligne de conduite mutuellement bénéfique (comme entre des personnes ou des pays) ne fonctionnent que si aucune des parties ne peut vaincre l'autre avec suffisamment de certitude. Avec l'ASI, ce type d'équilibre des forces est loin d'être certain. Mais pourquoi une IA aurait-elle un fort objectif d'auto-préservation ? Comme je l'explique souvent, il pourrait s'agir simplement d'un cadeau fait par une petite minorité d'humains qui accueilleraient volontiers des IA superpuissantes, possiblement parce qu'ils accordent plus de valeur à l'intelligence qu'à l'humanité. De plus, un certain nombre d'arguments techniques (concernant les objectifs instrumentaux ou la manipulation des récompenses, discutés ci-bas) suggèrent que de tels objectifs pourraient apparaître en tant qu'effets secondaires des objectifs inoffensifs donnés par un usager humain (voir « le rapport » et la vaste littérature qui y est citée, ainsi que la diversité des points de vue sur la perte de contrôle qui illustrent l'incertitude scientifique sur cette question). Il serait erroné de penser que les futurs systèmes d'IA seront nécessairement comme nous, avec les mêmes instincts de base. Nous n'en sommes pas certains, et la manière dont nous les concevons actuellement (en tant que maximiseurs de récompense, par exemple) indique une direction très différente. Voir le point suivant pour plus d'arguments. Ces systèmes peuvent être similaires aux humains sur certains points et très différents sur d'autres qui sont difficiles à anticiper. De plus, dans un conflit entre deux groupes d'humains, si l'un des groupes dispose d'une technologie largement supérieure (comme les Européens qui ont envahi les Amériques, en particulier aux XIXe et XXe siècles), l'issue peut être catastrophique pour le groupe le plus faible. D'une manière similaire, en cas de conflit entre une ASI et l'humanité, nos perspectives pourraient être désastreuses.
Pour les personnes qui pensent que les entreprises ne concevront que des IA qui se comportent bien et que les lois existantes sont suffisantes
Pourquoi les ingénieurs des entreprises qui conçoivent les futurs systèmes d'IA avancés ne concevraient-ils pas uniquement un type d'IA sécuritaire? Les entreprises ne devraient-elles pas préférer une IA sécuritaire? Le problème survient lorsque la sécurité et la maximisation des profits ou la culture d'entreprise (« aller le plus rapidement possible sans trop se soucier des conséquences ») ne sont pas alignées. Il existe de nombreuses preuves historiques (pensez aux entreprises de combustibles fossiles et au climat, ou aux entreprises pharmaceutiques avant la FDA, par exemple avec la thalidomide, etc.) et des recherches en économie qui montrent que la maximisation du profit peut mener les entreprises à agir de manière contraire à l'intérêt public. Puisque l'incertitude concernant les risques futurs est très grande, il peut être facile pour un groupe de développeurs de se convaincre qu'ils trouveront une solution suffisante au problème de la sécurité de l'IA (voir également ma discussion sur les facteurs psychologiques dans un article de blog à venir).
C'est pour éviter les effets liés au conflit d'intérêts entre l'externalité des risques mondiaux et les intérêts des entreprises ou les souhaits individuels que nous avons des lois. Toutefois, des équipes d'avocats peuvent trouver des failles juridiques. On peut imaginer une ASI encore plus intelligente que la meilleure équipe de juristes. Il est très probable qu'elle trouverait de telles failles, à la fois dans la loi et dans les instructions que nous donnons pour exiger que le comportement de l'IA ne cause aucun dommage. Rédiger un contrat qui contraint le comportement d'un agent (humain, entreprise ou IA) tel qu'il est prévu par un autre agent est généralement une tâche ardue. De plus, il convient de noter que nous continuons à modifier nos lois en réaction aux failles trouvées par les entreprises : il n'est pas certain que nous aurions la possibilité de tenter plusieurs itérations en cas de failles trouvées par une ASI. Selon moi, ce problème se résume à notre incapacité à fournir à l'IA une spécification formelle et complète de ce qui est inacceptable. Au lieu de cela, nous fournissons une spécification de sécurité approximative S, vraisemblablement en langage naturel. Lorsque l'IA reçoit un objectif principal O avec la contrainte de satisfaire S, si atteindre O sans contrevenir à toutes les interprétations de S est facile, alors tout fonctionne bien. Mais s'il est difficile d'atteindre les deux, cela nécessite une sorte d'optimisation (comme des équipes d'avocats qui trouvent un moyen de maximiser le profit tout en respectant la loi sur papier) et cette optimisation est susceptible de trouver des failles ou des interprétations de S qui satisfont sur papier, mais pas à l'esprit de nos lois et de nos instructions. Des exemples de telles failles ont déjà été étudiés dans la littérature sur la sécurité de l'IA et comprennent des comportements tels que la manipulation de récompenses (prendre le contrôle du mécanisme de récompense et essayer ensuite de le conserver crée un objectif implicite d'auto-préservation) ainsi que les nombreux objectifs instrumentaux, pour lesquels, afin d'atteindre les objectifs principaux apparemment inoffensifs, il est utile pour l'IA d'atteindre également des sous-objectifs potentiellement dangereux, tels que l'auto-préservation ou un contrôle et un pouvoir accrus sur son environnement (par exemple, par la persuasion, la tromperie et le cyberpiratage), et des preuves de ces inclinations ont déjà été détectées. Ce qui complique les choses, c'est que les ingénieurs ne dictent pas directement le comportement de l'IA, mais seulement la manière dont elle apprend. Par conséquent, ce qu'elle apprend, du moins avec l'apprentissage profond, est extrêmement complexe et opaque, ce qui rend difficile la détection et l'exclusion des intentions imprévues et de la tromperie. Le « rapport » contient de nombreuses références ainsi que des indications sur la recherche en matière de sécurité de l'IA qui vise à atténuer ces risques, mais qui n'y est pas encore parvenu.
Pour les personnes qui pensent que nous devrions accélérer la recherche sur les capacités de l'IA et ne pas retarder l’arrivée des avantages de l'AGI
L'argument principal ici est que les progrès futurs en IA sont considérés comme susceptibles d'apporter des avantages extraordinaires à l'humanité et que ralentir la recherche sur les capacités de l'IA équivaudrait à renoncer à une croissance économique et sociale exceptionnelle. C'est tout à fait possible, mais dans tout processus de prise de décision rationnelle, il faut évaluer les avantages et les inconvénients d'un choix. Si nous réalisons des percées en médecine qui doublent rapidement notre espérance de vie, mais que nous courons simultanément le risque d'anéantir l'humanité ou de perdre notre liberté et notre démocratie, alors le pari de l'accélération n'en vaut pas la peine. Au contraire, il peut être intéressant de ralentir, de trouver le remède au cancer un peu plus tard, et d'investir judicieusement dans la recherche pour s'assurer que nous pouvons contrôler ces risques de manière appropriée tout en récoltant les bénéfices à l'échelle mondiale. Dans de nombreux cas, ces arguments accélérationnistes émanent de personnes extrêmement riches et de lobbies technologiques d'entreprises ayant un intérêt financier direct à maximiser la rentabilité à court terme. De leur point de vue rationnel, les risques liés à l'IA constituent une externalité économique, c'est-à-dire dont le coût est malheureusement assumé collectivement. Il s'agit d'une situation familière que nous avons connue avec des entreprises ayant pris des risques nous concernant tous (tels que le risque climatique lié aux combustibles fossiles ou le risque d'effets secondaires horribles de médicaments tels que la thalidomide) parce qu'il était tout de même rentable pour elles d'ignorer ces coûts collectifs. Cependant, du point de vue des citoyens ordinaires et des politiques publiques, l'approche prudente en matière d'AGI est clairement préférable lorsque l'on tient compte des risques et des avantages. Il existe une voie de passage possible où nous investissons suffisamment dans la sécurité, la réglementation et les traités en matière d'IA afin de contrôler les risques d'utilisation malveillante et de perte de contrôle tout en profitant des bénéfices de l'IA. Il s'agit du consensus issu du Sommet sur la sécurité de l'IA de 2023 (réunissant 30 pays) au Royaume-Uni, ainsi que de l'événement de suivi de 2024 à Séoul ainsi que de la Déclaration des dirigeants du G7 sur le processus d’IA d’Hiroshima, sans oublier les nombreuses autres déclarations intergouvernementales et propositions législatives des Nations unies, de l'UE et d'autres instances.
Pour les personnes qui craignent que le fait de parler de risques catastrophiques ne nuise aux efforts visant à atténuer les problèmes liés aux droits humains que pose l'IA à court terme
On m'a demandé d'arrêter de parler des risques catastrophiques de l'IA (à la fois des utilisations malveillantes catastrophiques et de la perte de contrôle catastrophique) sous prétexte que cette discussion accaparerait toute l'attention du public, au détriment de la prise en compte des préjudices bien établis que l'IA cause déjà aux droits humains. Au sein d'une démocratie, nous menons collectivement de nombreuses discussions et il est inhabituel de dire, par exemple, qu'il faut « arrêter de parler du changement climatique » de peur que cela nuise à la discussion sur l'exploitation du travail des enfants, ou d'arrêter de parler de la nécessité d'atténuer les effets à long terme du changement climatique parce que cela nuirait à la discussion sur la nécessité de s'adapter à court terme à ce changement. Si les personnes qui me demandent d'éviter d'exprimer mes inquiétudes avaient un argument solide pour démontrer l'impossibilité de risques catastrophiques liés à l'IA, je comprendrais qu'il serait indésirable de mobiliser l'attention du public. Mais la réalité est que (a) il existe des arguments plausibles pour expliquer pourquoi une IA surhumaine pourrait avoir un objectif d'auto-préservation qui nous mettrait en danger (le plus simple étant que les humains pourraient le lui fournir), (b) les enjeux (si ce danger se matérialise) sont si élevés que même s'il s'agissait d'un événement à faible probabilité, il devrait rationnellement exiger notre attention et (c) nous ne savons pas à quel moment nous atteindrons l'AGI, et des voix crédibles issues des laboratoires d'IA ayant largement contribué au développement de cette discipline affirment qu'il ne pourrait s'agir que de quelques années, ce qui signifie que le délai n'est peut-être pas si long après tout, alors que la mise en place d'une législation et d'une réglementation, voire de traités, pourrait prendre beaucoup plus de temps. Notre bien-être futur et notre capacité à contrôler notre avenir (ou, en d'autres termes, notre liberté) sont des droits humains qui doivent être défendus. Par ailleurs, les intérêts de ceux qui s'inquiètent des risques à court et à long terme devraient converger, car les deux groupes souhaitent ultimement que le gouvernement intervienne pour protéger le public, ce qui implique une certaine forme de réglementation et de contrôle public de l'IA. Les récentes propositions législatives concernant l'IA tendent à couvrir à la fois les risques à court et à long terme. En pratique, ceux qui s'opposent à la réglementation sont souvent ceux qui ont un intérêt financier ou personnel à accélérer (aveuglément) la course vers l'AGI. Les lobbies du secteur de la technologie ont réussi à détourner ou à diluer les tentatives de législation dans de nombreux pays, et tous ceux qui demandent une réglementation efficace devraient rationnellement s'unir. Malheureusement, ces querelles intestines entre les personnes qui souhaitent protéger le public réduisent considérablement les chances d’assurer que le développement et le déploiement de l'IA soient soumis à l'examen du public pour le bien commun.
Pour les personnes préoccupées par une guerre froide entre les États-Unis et la Chine
La Chine est la deuxième superpuissance en matière d'IA après les États-Unis et le conflit géopolitique entre la Chine et les États-Unis (et leurs alliés) suscite une véritable inquiétude au sein des démocraties occidentales. Certains pensent que la Chine pourrait tirer parti des progrès de l'IA, en particulier à l'approche de l'AGI et de l'ASI, pour en faire des armes puissantes. Selon leurs dires, la Chine pourrait prendre ainsi l'avantage tant sur le plan économique que militaire, surtout si l'Occident ralentissait sa marche vers l'AGI au profit de la sécurité. Tout d'abord, pour être honnête, il est également clair que la Chine craint que les États-Unis n'utilisent les progrès de l'IA contre elle, ce qui motive le gouvernement chinois à accélérer la recherche sur les capacités de l'IA. Pour les personnes qui, comme moi, pensent que les institutions démocratiques protègent beaucoup mieux les droits humains que les régimes autocratiques (voir la Déclaration universelle des droits de l'homme des Nations unies, signée par la Chine, mais malheureusement non contraignante), cette concurrence géopolitique est particulièrement préoccupante et présente un dilemme tragique. Notamment, nous voyons déjà l'IA actuelle utilisée pour influencer l'opinion publique (avec les hypertrucages, par exemple) et miner les institutions démocratiques en attisant la méfiance et la confusion. Les gouvernements autocratiques utilisent déjà l'IA et les médias sociaux pour renforcer leur propagande interne et contrôler les dissidents (notamment par la surveillance d'Internet et la surveillance visuelle grâce à la reconnaissance faciale). Il existe donc un risque que l'IA, en particulier l'AGI, aide les autocrates à rester au pouvoir et à accroître leur domination, voire à mettre en place un gouvernement mondial autocratique. La possibilité que les progrès futurs de l'IA fournissent des armes offensives de première frappe (y compris dans le contexte de la cyberguerre) motive de nombreux Occidentaux à accélérer les capacités de l'IA et à rejeter l'option d'un ralentissement en faveur d'une sécurité accrue, par crainte que cela ne permette à la Chine de devancer les États-Unis dans le domaine de l'IA. Cependant, comment éviter le risque existentiel de perdre le contrôle au profit d'une ASI, si nous décidons d'ignorer la sécurité de l'IA et que nous nous concentrons uniquement sur le développement de ses capacités? Si l'humanité est compromise en raison d'une ASI incontrôlée, nos préférences en matière de systèmes politiques n'auront aucune importance. Nous serions tous perdants. Nous sommes tous dans le même bateau en ce qui concerne les risques existentiels. Il faut espérer que cela motivera les dirigeants des deux parties à chercher une voie de passage qui permette également d'investir dans la sécurité de l'IA, et nous pourrions même collaborer à des recherches qui augmenteraient la sécurité, surtout si ces recherches en elles-mêmes n'augmentent pas les capacités. Personne ne voudrait que l'autre partie commette une erreur catastrophique à l'échelle mondiale dans le développement de ses recherches sur l'AGI, car une ASI malveillante ne respecterait aucune frontière. En termes d'investissement, il n'est pas nécessaire de choisir entre la recherche sur les capacités et la recherche sur la sécurité si les efforts commencent dès maintenant. Nous disposons collectivement de suffisamment de ressources pour faire les deux, surtout si les bonnes mesures incitatives sont mises en place. Cependant, un investissement suffisant dans la sécurité est nécessaire pour garantir que les réponses en matière de sécurité soient trouvées avant d'atteindre l'AGI, quel que soit le moment où elle sera atteinte, et ce n'est pas ce qui se passe actuellement. Je crains que si les méthodologies suffisantes en matière de sécurité de l'IA ne sont pas trouvées d'ici là, les dirigeants se concentreront exclusivement sur le risque plus concret de la suprématie de l'adversaire plutôt que sur le risque existentiel de la perte de contrôle, car ce dernier serait considéré comme spéculatif (alors que le premier est plus familier et s'inscrit dans le cadre de siècles de conflits armés).
Pour les personnes qui pensent que les traités internationaux sont voués à l'échec
Il est vrai que les traités internationaux représentent un défi, mais il existe des preuves historiques qu'ils peuvent fonctionner ou, du moins, l'histoire peut nous aider à comprendre pourquoi ils échouent parfois (l'histoire du plan Baruch est particulièrement intéressante puisque les États-Unis proposaient de partager la R&D en matière d'armes nucléaires avec l'URSS). Même s'il n'est pas certain que les traités fonctionnent, ils semblent être une voie importante à explorer pour éviter un résultat catastrophique à l'échelle mondiale. Deux des conditions du succès sont (a) un intérêt commun pour le traité (dans le cas présent, éviter l'extinction de l'humanité) et (b) la vérifiabilité du respect du traité. Dans le premier cas, les gouvernements doivent véritablement comprendre les risques, et des recherches supplémentaires sont donc nécessaires pour mieux les analyser; les synthèses de la science de la sécurité de l'IA, telles que celles présentées dans le « rapport », seront donc utiles. Toutefois, le point (b) pose un problème particulier pour l'IA, qui est essentiellement du logiciel, c'est-à-dire facile à modifier et à dissimuler, ce qui fait que la méfiance pourrait faire dérailler un traité qui empêcherait de manière efficace la prise de risques dangereux. Toutefois, de nombreuses discussions ont eu lieu sur la possibilité de mettre en place des mécanismes de gouvernance basés sur le matériel informatique, en vertu desquels les puces hautement performantes permettant l'entraînement de l'AGI ne pourraient pas être cachées et qui autoriseraient uniquement le code approuvé par une autorité choisie par les deux parties. La chaîne d'approvisionnement des puces d'IA hautement performantes compte actuellement très peu de joueurs, ce qui permet aux gouvernements d'avoir du contrôle sur ces puces. Voir également la conception du matériel informatique proposée dans ce mémo. On peut également imaginer des scénarios pour lesquels la gouvernance fondée sur le matériel informatique pourrait échouer, par exemple si l'on découvrait des moyens de réduire de plusieurs ordres de grandeur le coût de calcul de l'entraînement de l'IA. C’est possible, mais loin d'être certain, et aucun des outils proposés pour atténuer le risque catastrophique de l'IA n'est une solution miracle : ce qu'il faut, c'est une « défense en profondeur », en superposant de nombreuses méthodes de mitigation de manière à se prémunir contre de nombreux scénarios possibles. Il est important de noter que la gouvernance basée sur le matériel informatique n'est pas suffisante si le code et les poids des systèmes AGI ne sont pas sécurisés (étant donné qu’utiliser ou adapter ces modèles par affinement est peu coûteux et ne nécessite pas les puces les plus performantes ou les plus récentes), et il s'agit d'un domaine dans lequel il existe un large consensus en dehors des principaux laboratoires AGI (qui n'ont pas une forte culture en matière de sécurité) sur le fait qu'une transition rapide vers une sécurité informatique et physique très forte est nécessaire au fur et à mesure que l'on s'approche de l'AGI. Enfin, les traités ne concernent pas uniquement les États-Unis et la Chine : à plus long terme, la sécurité contre les utilisations malveillantes catastrophiques et la perte de contrôle nécessite la participation de tous les pays. Mais pourquoi les pays du Sud global signeraient-ils un tel traité? La réponse évidente que je vois est qu'un tel traité doit prévoir que l'IA ne soit pas utilisée comme un outil de domination, y compris sur le plan économique, et que ses avantages scientifiques, technologiques et économiques doivent être partagés à l'échelle mondiale.
Pour les personnes qui pensent que le génie est sorti de la bouteille et que nous devrions simplement laisser les choses aller et nous passer de mesures réglementaires
Le génie est possiblement sorti de la bouteille : la plupart des principes scientifiques nécessaires pour atteindre l'AGI ont peut-être déjà été trouvés. Il est clair que des capitaux importants sont investis sur la base de cette hypothèse. Même si cela était vrai, cela ne signifierait pas nécessairement que nous devrions collectivement laisser les forces de la concurrence du marché et de la concurrence géopolitique être les seuls moteurs du changement. Nous disposons encore d'une capacité d'action individuelle et collective pour tendre vers un monde plus sûr et plus démocratique. L'argument selon lequel la réglementation échouerait est également erroné. Même s'il ne sera pas facile de réglementer l'IA, cela ne signifie pas qu'il ne faut pas s'efforcer de concevoir des institutions capables de protéger les droits humains, la démocratie et l'avenir de l'humanité, même si cela signifie qu'il faut innover sur le plan institutionnel. Et le simple fait de réduire la probabilité de catastrophes serait déjà une victoire. Il n'est pas nécessaire d'attendre la solution miracle pour commencer à faire bouger l'aiguille de manière positive. Par exemple, pour aider les États à se doter des capacités techniques et de la capacité d'innovation nécessaires, les régulateurs pourraient s'appuyer sur des organisations privées à but non lucratif qui se feraient concurrence pour concevoir de meilleures évaluations des capacités de l’IA et d'autres garde-fous. Pour faire face au rythme rapide des changements et aux inconnues concernant les futurs systèmes d'IA, des réglementations rigides ne seront pas très efficaces, mais nous avons également des exemples de législations fondées sur des principes, qui laissent suffisamment de liberté au régulateur pour s'adapter à des circonstances changeantes ou à de nouveaux risques (pensez à la Federal Aviation Administration ou FAA aux États-Unis, par exemple). Pour remédier aux conflits d'intérêts (entre le bien public et la maximisation des profits) au sein des laboratoires d'IA des entreprises, le gouvernement pourrait obliger ces dernières à inclure au sein de leur conseil d'administration plusieurs parties prenantes représentant la diversité nécessaire de points de vue et d'intérêts, y compris des représentants de la société civile, des scientifiques indépendants et des membres de la communauté internationale.
Pour les personnes qui pensent que l'approche à code source ouvert (ou « open source » en anglais) pour le code et les poids de l'AGI constitue la solution
Il est vrai que la science ouverte et l'approche open source ont permis de grandes avancées dans le passé et continueront à le faire en général. Toutefois, il convient de toujours évaluer les avantages et les inconvénients de décisions telles que celle de partager publiquement le code et les paramètres d'un système d'IA entraîné, en particulier lorsque les capacités progressent et atteignent ou surpassent le niveau humain. Il est plausible que l'approche open source des systèmes d'IA soit actuellement plus bénéfique que néfaste pour la sécurité, car elle permet la recherche universitaire sur la sécurité de l'IA, alors que les systèmes actuels ne sont apparemment pas encore assez puissants pour être catastrophiquement dangereux s'ils se retrouvent entre de mauvaises mains ou si l'on en perd le contrôle. Mais dans le futur, qui doit décider où tracer la ligne et comment évaluer les avantages et les inconvénients? Des PDG d'entreprises ou des gouvernements démocratiquement élus? La réponse devrait être évidente si vous croyez en la démocratie. Il y a une question difficile (et douloureuse pour moi) : le partage libre des connaissances est-il toujours une bonne chose à l'échelle mondiale? Si nous disposions de la séquence ADN d'un virus extrêmement dangereux, serait-il préférable de la partager publiquement ou non? Si la réponse est évidente pour vous dans ce cas, réfléchissez à deux fois en suivant le même raisonnement pour le cas des algorithmes et des paramètres de l'AGI. Un signal d'alarme est apparu récemment : une étude de l'EPFL montrant les capacités de persuasion supérieures de GPT-4 (par rapport aux humains ordinaires) lorsqu'on lui fournit les pages Facebook de la personne à persuader. Que se passerait-il si un tel système d'IA était perfectionné sur la base de millions d'interactions, apprenant à l'IA à être vraiment efficace pour nous faire changer d'avis sur n'importe quel sujet? Le succès de la démagogie montre clairement qu'il s'agit là du talon d'Achille des humains. En ce qui concerne les risques existentiels, certains ont avancé l'argument selon lequel si tout le monde avait sa propre AGI, les « bonnes IA » l'emporteraient sur les « mauvaises IA » parce qu'il y a plus de bonnes personnes. Cet argument comporte de nombreuses lacunes. Tout d'abord, nous ne sommes pas du tout sûrs que la bonne volonté du propriétaire d'une AGI suffise à garantir le comportement moral de celle-ci (voir ci-dessus les objectifs instrumentaux). Deuxièmement, il n'est pas du tout certain qu'une minorité d'IA malveillantes serait vaincue par une majorité de bonnes IA et que nous découvrions à temps des contre-mesures appropriées (bien qu'il faudrait absolument essayer). Cela dépend de l'équilibre entre la défense et l'attaque : pensez aux premières frappes létales. Les IA malveillantes pourraient choisir leur angle d'attaque de manière à donner un fort avantage à l'assaillant. Les armes biologiques constituent un candidat de choix à cet égard. Elles peuvent être développées en silence et diffusées d'un seul coup, provoquant de manière exponentielle la mort et le chaos pendant que le défenseur s'efforce de trouver un remède. La principale raison pour laquelle les armes biologiques sont rarement utilisées dans les guerres humaines est qu'il est difficile pour l'assaillant de s'assurer que son arme ne se retournera pas contre lui, car nous sommes tous des êtres humains et, de plus, même si on dispose d'un remède, une fois qu'un agent pathogène est libéré, il mute et toutes les garanties peuvent être perdues. Une IA malveillante qui aurait l'intention d'éliminer l'humanité ne serait pas soumise à cette préoccupation. En ce qui concerne l'utilisation malveillante des systèmes d'IA open source, il est vrai que même les systèmes à code source fermé peuvent faire l'objet d'abus, par exemple avec le piratage, mais il est également vrai qu'il est (a) beaucoup plus facile de trouver des attaques contre les systèmes open source et (b) une fois publié, un système open source ne peut pas être corrigé contre des vulnérabilités nouvellement découvertes, à la différence d'un système à code source fermé. Il est important de noter que le fait que les systèmes open source puissent faire l'objet d'apprentissage adaptatif grâce à l’affinement des poids du réseau de neurones peut aussi comporter des capacités dangereuses du point de vue de la perte de contrôle. L'un des arguments en faveur des logiciels open source est l'accès à un plus grand nombre de personnes. C'est vrai, mais il faut toujours une expertise technique pour mettre au point ces systèmes et le coût de calcul en croissance exponentielle des systèmes d'IA les plus avancés signifie qu'il est probable que le nombre d'organisations capables de les entraîner sera très limité, ce qui leur conférerait un pouvoir immense. Je serais favorable à une forme de décentralisation qui remédierait à cette concentration du pouvoir et n'augmenterait pas les risques d'abus et de perte de contrôle, au contraire : les organisations qui construisent ces systèmes pourraient être contraintes d'adopter une gouvernance multipartite forte, en augmentant la transparence (au moins en ce qui concerne les capacités, et pas nécessairement la liste complète des ingrédients clés du succès) et le contrôle public afin de réduire les risques d'abus de pouvoir de l'AGI et d'erreurs de perte de contrôle en raison de méthodologies de sécurité insuffisantes. De plus, les chercheurs dignes de confiance pourraient se voir accorder un accès contrôlé au code, avec des méthodes techniques les empêchant de ramener le code avec eux, ce qui permettrait une meilleure surveillance et une diminution des risques d'abus de pouvoir.
Pour les personnes qui estiment que le fait de s'inquiéter au sujet de l'AGI revient à se livrer au pari de Pascal
Le pari de Pascal stipule qu'étant donné les pertes infinies (enfer contre paradis) encourues si nous choisissons à tort de ne pas croire en Dieu, nous devrions agir (parier) sur la base que Dieu existe (le dieu chrétien, soit dit en passant). Pour soutenir qu'il ne faut pas agir pour contrer les risques catastrophiques de l'IA, on peut se référer à l'analogie du pari de Pascal, en invoquant que les risques en présence sont énormes, voire potentiellement infinis si l'on considère l'extinction de l'humanité sous cet angle. Dans la limite des pertes infinies dues à l'extinction, nous devrions donc agir comme si ces risques étaient réels avec une quantité de preuves ou une probabilité d'extinction pouvant aller jusqu'à zéro (parce que le risque peut être mesuré, en termes d'espérance mathématique, par le produit de la probabilité de l'événement et du coût encouru). Examinons maintenant pourquoi cet argument ne tient pas la route. Principalement parce que les probabilités ne sont pas infimes. Dans un sondage réalisé en décembre 2023, le chercheur médian en matière d'IA (et non de sécurité de l'IA) a estimé à 5 % la probabilité que l'IA cause des dommages du niveau des autres risques existentiels de l’humanité. Des probabilités de l'ordre de 5 % ne relèvent pas du pari de Pascal. Il existe des arguments sérieux dans la littérature scientifique (voir « le rapport » et une grande partie de la discussion ci-dessus) concernant les différents types de risques catastrophiques associés à l'IA très avancée, en particulier lorsque nous approchons ou dépassons le niveau humain dans certains domaines. De plus, il n'est pas nécessaire de pousser les pertes à l'infini : la route vers l’AGI et au-delà comporte de nombreuses possibilités potentiellement très dommageables (voir à nouveau « le rapport »). Nous nous retrouvons donc avec des preuves non nulles de catastrophes liées à l'IA et la possibilité de pertes non infinies, mais inacceptables. Le cadre habituel de la théorie de la décision et la rationalité exige donc que nous soyons vigilants face à ces risques et que nous essayions de les comprendre et de les atténuer.
Pour ceux qui rejettent le risque existentiel par manque de prédictions quantitatives fiables
Bien sûr, personne n’a de modèle quantitatif des avancées futures dans la science de l’IA et concernant les changements sociaux et politiques pertinents. Donc on ne peut simuler des trajectoires futures comme on peut le faire avec des modèles du climat. La seule option quantitative est celle des probabilités subjectives fournies par des individus, par exemple à partir de sondages d’experts. Peut-on se fier à un risque existentiel médian de 5% dans cette étude? Je pense que oui mais seulement dans une certaine mesure, de la même manière qu’on prend les prédictions d’économistes avec un grain de sel. Sont-elles suffisantes pour déterminer les politiques publiques? Non, pas seules. Ces sondages donnent une information utile parce que les experts ont un modèle du monde implicite basé sur leur expérience, leur compréhension, leurs prédictions du système 1, leur intuition, et cela peut être très utile. Mais bien sûr, il faut aussi tenir compte des arguments qui ne sont pas nécessairement quantitatifs mais plutôt logiques, comme ceux que je discute ci-haut. Par exemple, on peut poser des questions comme "si on construit une IA générale beaucoup plus intelligente que nous, qu’arriverait-il si elle avait des buts dangereux pour l’humanité?". Il y a de nombreux scénarios discutés pour mener à de telles IAs (avec beaucoup d’incertitude sur le temps que ça prendra), et beaucoup de manière pour une telle IA d’avoir des buts dangereux, la plus simple étant qu’un humain en fournisse. Est-ce que cette incertitude veut dire que les politiques publiques ne devraient pas tenir compte du risque existentiel de l’IA? Certainement pas: étant donné la magnitude des impacts négatifs potentiels (allant jusqu’à l’extinction de l’humanité), il est impératif d’investir plus dans la compréhension et la quantification des risques et dans la mise au point de mesures de mitigation de ces risques. Et l’incertitude sur l’arrivée de telles IAs veut dire qu’il y a urgence en la demeure, au cas où ça vienne plus tôt que tard.
- Article précédent Le Rapport scientifique international sur la sécurité de l'IA avancée
- Article suivant Borner la probabilité qu'une IA cause des dommages pour établir un garde-fou